Unchained Hashtable
A hybrid design combining the best of open addressing and chaining to handle skewed data distributions efficiently.
The Need for Robustness
Hash join performance is critical for overall database system efficiency. However, predicting the nature of intermediate results is difficult.
An ideal hash join implementation must be fast for typical queries and robust against unusual data distributions (e.g., highly skewed data or duplicates).
The Unchained Hashtable combines build-side partitioning, adjacency array layout, pipelined probes, Bloom filters, and software write-combine buffers to achieve this balance.
Key Features
- Adjacency Array: Dense storage without linked list overhead.
- Bloom Filters: Early rejection of non-matching probes.
- Pipelined Probes: Maximizing CPU instruction throughput.
Unchained Architecture
Open addressing is fast for non-selective predicates but struggles with duplicates and high selectivity. Chaining handles duplicates well but suffers from pointer chasing overhead.
The Unchained Hashtable eliminates expensive pointer chasing by using a dense adjacency array. Tuples are stored in a contiguous buffer sorted by their hash prefixes. A separate directory points to the start of each prefix range.
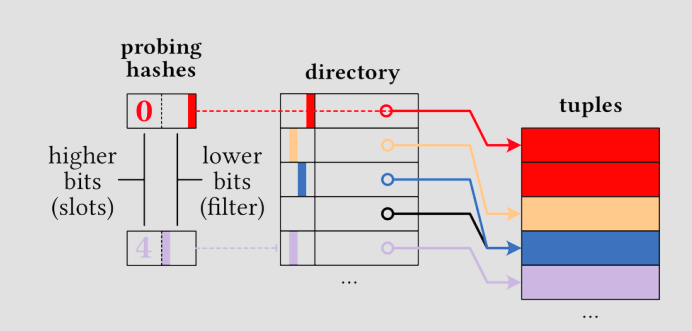
Figure 1: Hashtable Layout. The directory entries point to ranges of tuples in a contiguous buffer. Each entry also contains a tiny Bloom filter for early pruning.
Directory & Bloom Filters
Since joins are often highly selective, eliminating non-matching tuples early is crucial. We embed a register-sized Bloom filter (16 bits) directly into each directory slot.
Optimization: Modern systems use only the lower 48 bits for addressing. We utilize the unused upper 16 bits of pointers to store this Bloom filter.
Efficient Probing
The probe phase is typically the most expensive part of a join. Our approach minimizes work per tuple:
- Hash: Compute hash of the probe key.
- Directory Lookup: Use hash prefix to index into directory.
- Filter Check: Check the 16-bit Bloom filter. If mismatch, discard tuple immediately (skip memory access).
- Scan: If match, follow the pointer and scan the contiguous range of potential matches in the buffer.
Implementation Strategy
-
Hashing Functions
We experiment with CRC32 and Fibonacci hashing to find the fastest distribution for our keys. The goal is to balance speed with collision minimization.
-
Precomputed Popcounts
For the Bloom filters, we can precompute
popcountfor all possible 16-bit hash prefixes to accelerate the filter construction phase. -
Single Partition (Initial)
For this milestone, we construct a single partition during the build phase. Future optimizations will focus on parallelizing this construction.